
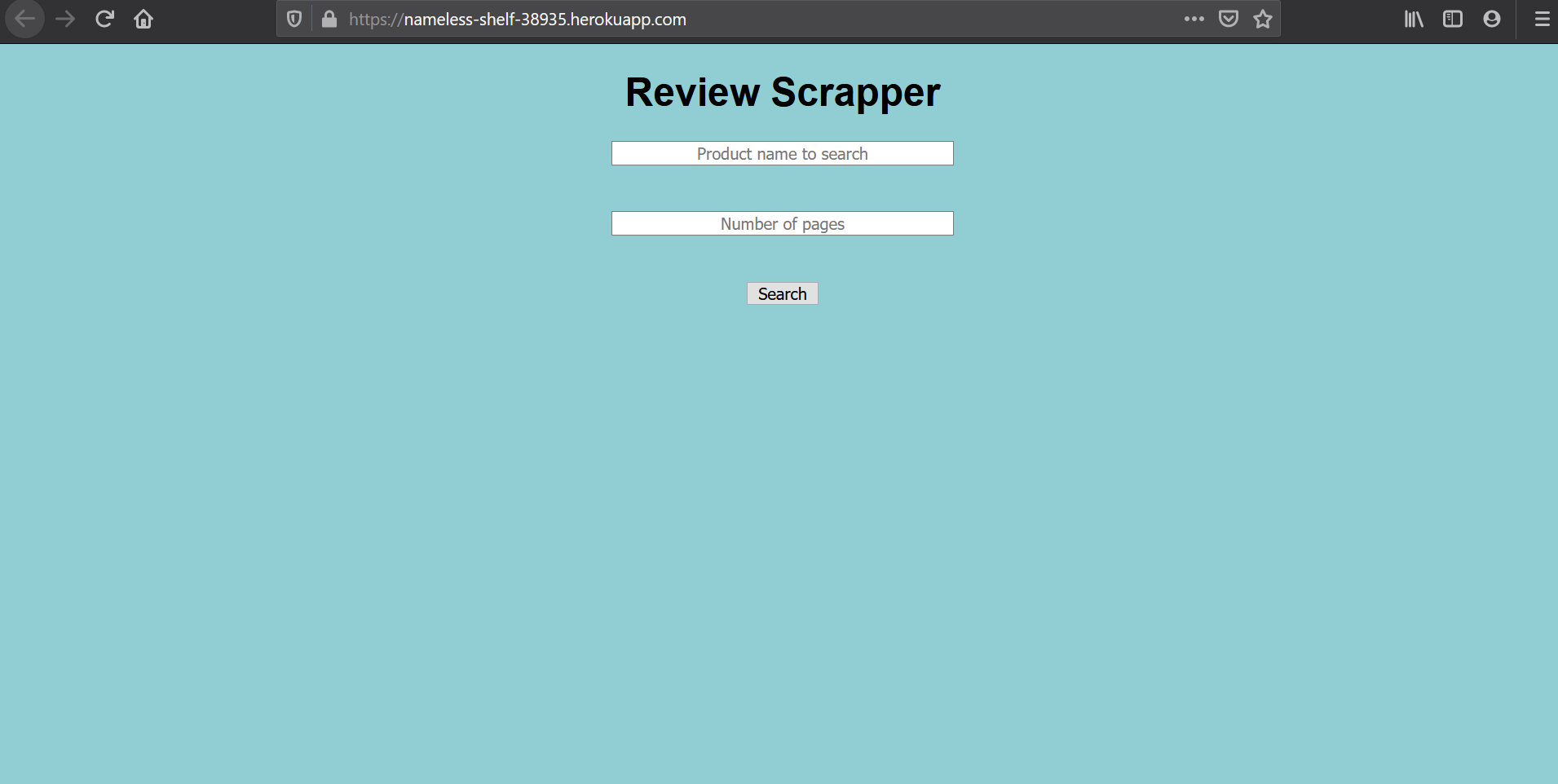
Building a review scrapper web app with heroku deployment for collecting data.
| Home | Results |
|---|---|
 |
 |
Why build this app?
- I wanted to learn web scrapping, deployment using one of the many platforms available, connecting py files with html and using a database server to store data on a local machine.
- This project seemed to me as the ideal mix of whatever I wanted to learn while also building a useful tool for myself.
- My vision at the time was to use the output of the app to further analyze the reviews and get relevant analysis for different products.
- I have no intentions of commercializing this product and have only made this for learning purposes.
Overall functionality
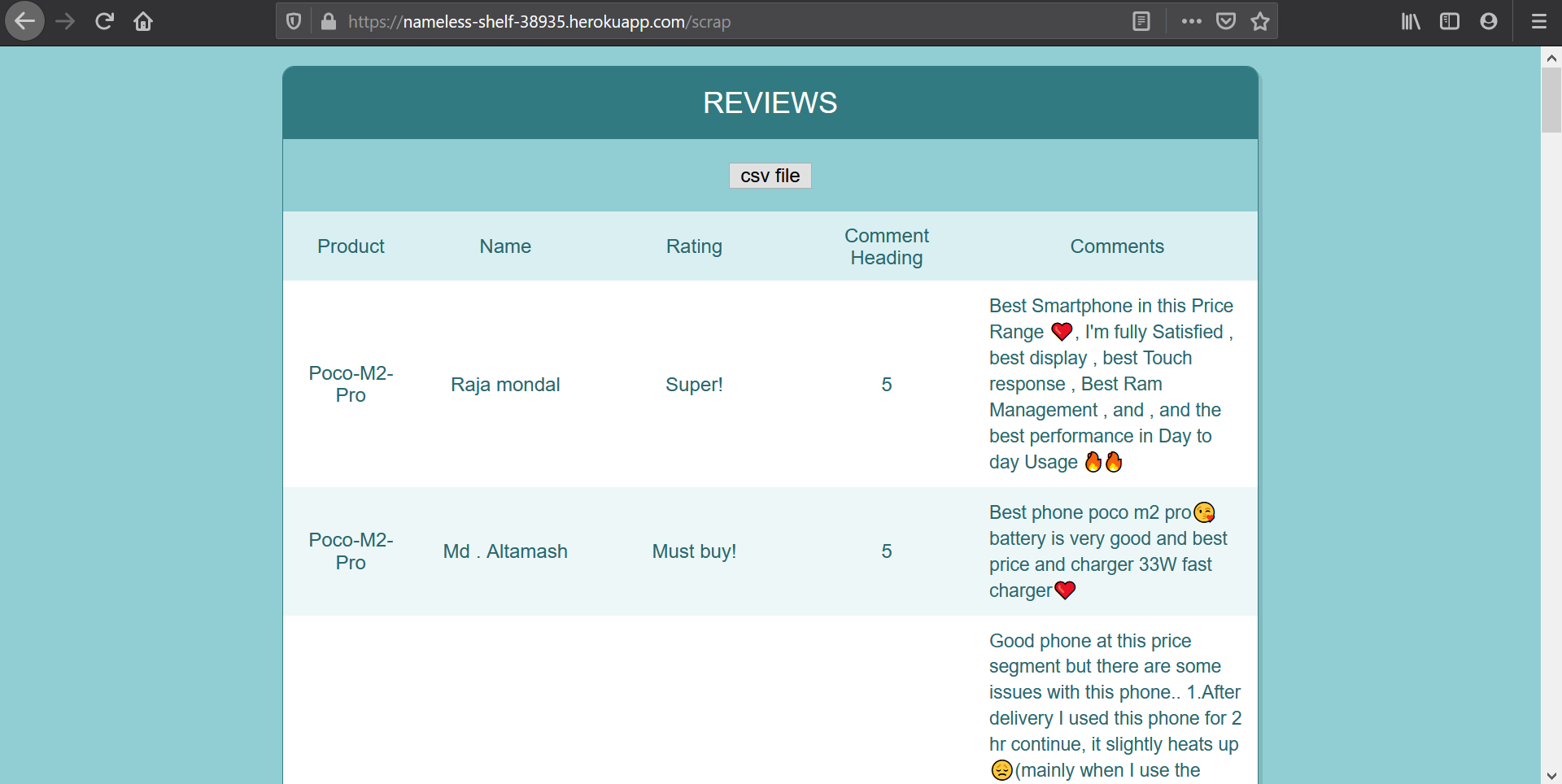
- Takes 2 inputs from user. 1 is the product to search and 2nd is the number of pages of reviews to scrap.
- Once results page loads with reviews, the app provides a csv file button to download all reviews as a csv for further analysis.
This app operates differently on a local machine due to certain restrictions I faced on the deploying platform
Tools used
- Pycharm Community edition 2020.1.1
- Python 3.6.12
- MongoDB server 1.21.2
- git 2.28.0
- Heroku cli 7.42.13
Main Libraries used. (Rest in requirements.txt)
- Beautiful Soup: For beautiful web scrapping.
- Flask: Container for app deployment. Also has tools like requests which allow for url access.
- Pandas: To create a csv file for the reviews.
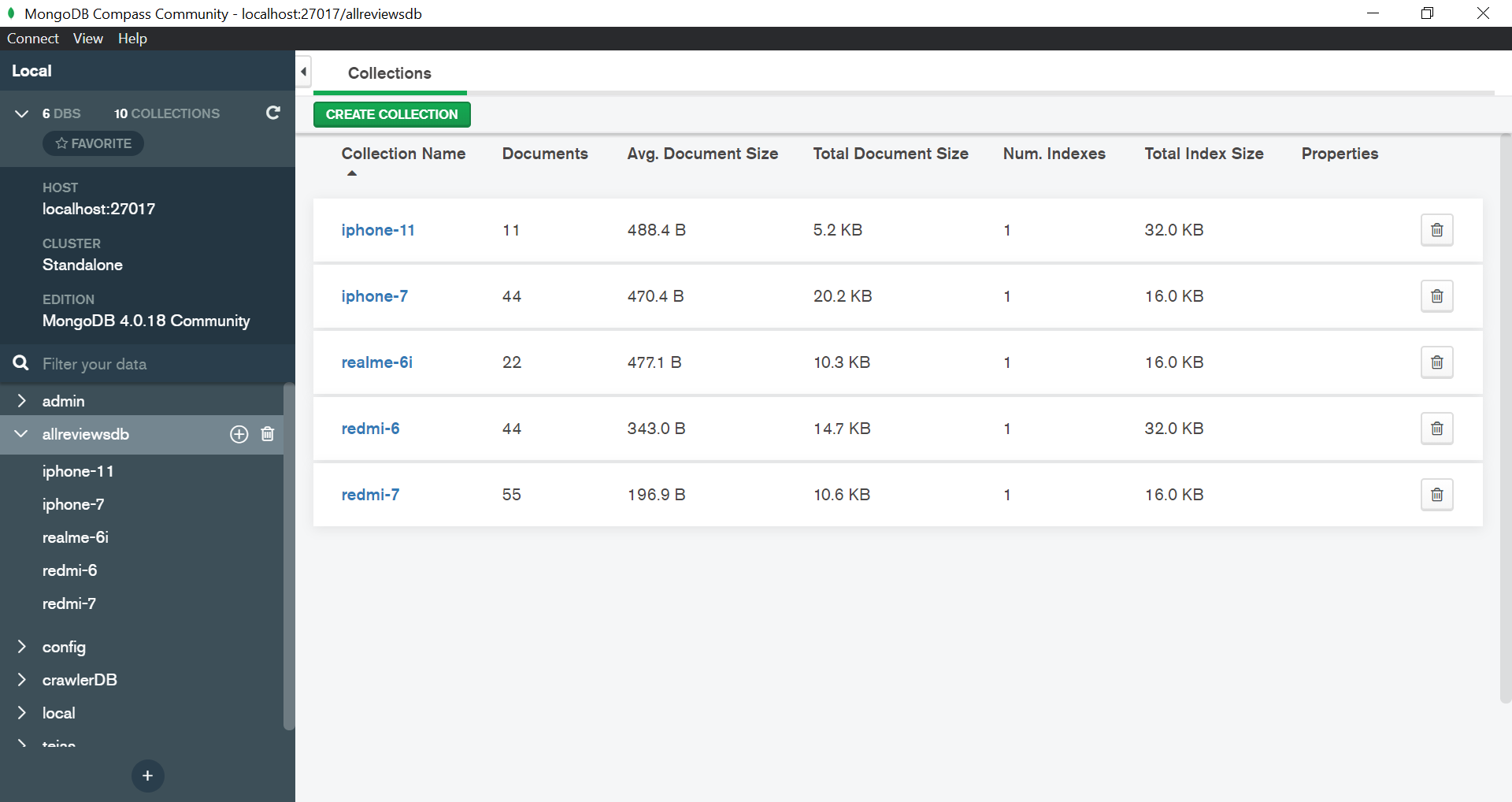
Local version
| MongoDB Database | redmi-7 reviews in Mongo Server |
|---|---|
 |
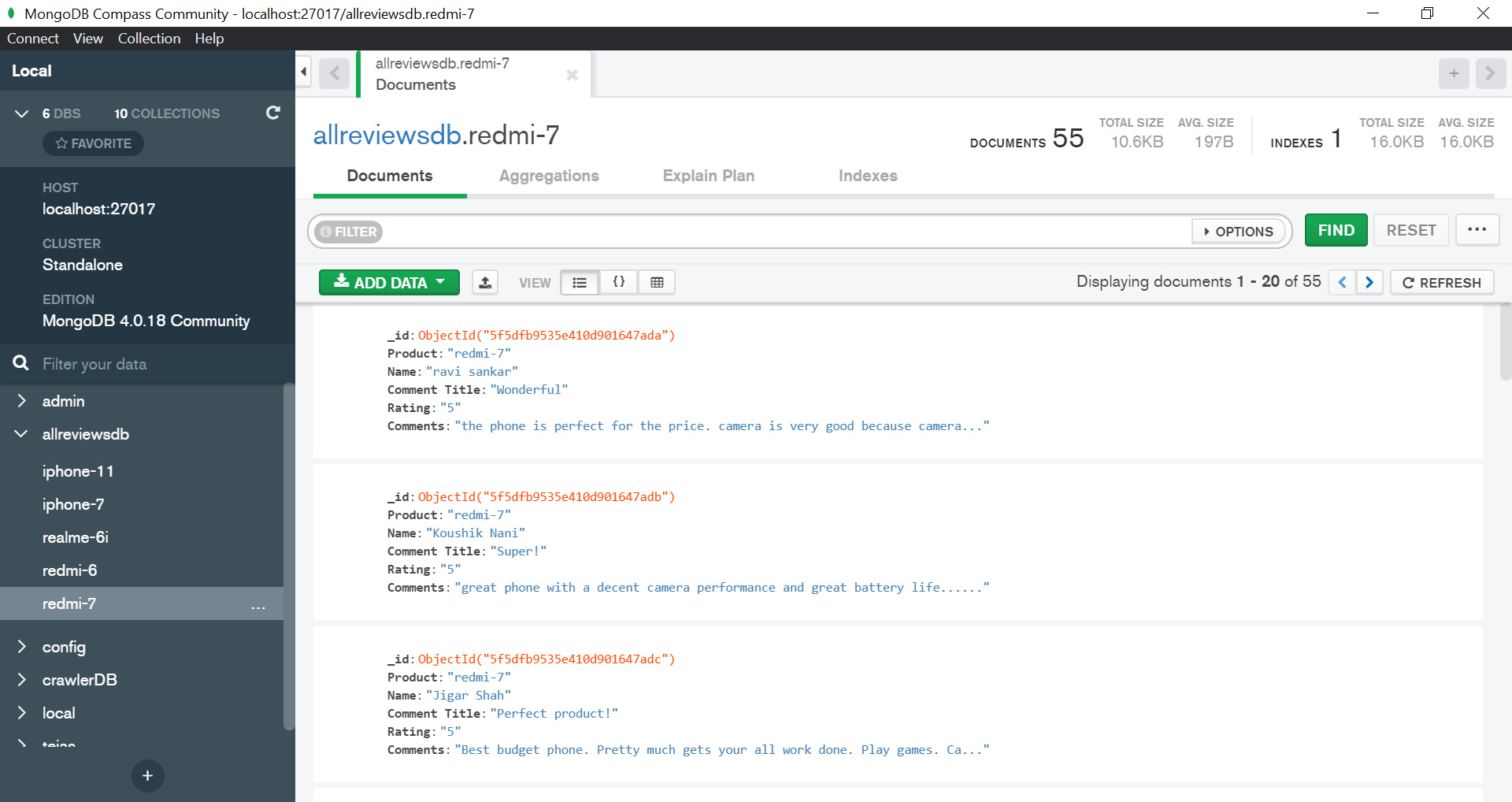 |
- On the local version the app can scrap as many pages as the user wants for almost any product on Flipkart.
- The scrapped reviews are then saved on a local MongoDB server.
Online Version
- For the deployment I went for Heroku since it was easy to learn.
- Heroku offers 500MB of storage in their free tier which I opted for since this project is only for learning purposes.
- With heroku I had to make certain changes to my project.
Changes made
- Created a new app.py file containing the same code as the flask app.
- Removed the db component from app.py since that is a paid service on heroku.
- Created a procFile with web:gunicorn app for heroku to build files accordingly. Without this the app will always crash.
Steps for deployment
- Create a requirements.txt file using pip freeze >requirements.txt. This will store all our library names in a text file. This will be used by heroku to install all the dependancies.
- Install git
- Create a git init folder within the app folder through command prompt.
- Run git add . to add files that we want to commit.
- Run git commit -m “ “ to make the files ready for being committed to heroku.
- Download heroku cli
- Run heroku login command to login to your dashboard on cmd.
- Run heroku create to create the app.
- Run git remote -v to establish connection.
- Run git push heroku master
Limitation of this deployed version
- The deployed version of this project cannot scrap more than 2 pages of reviews.
- The reason behind this is that Heroku needs a request to be sent back to it within 30s which my code cannot do beyond 2 pages.
- A workaround is to use background requests to bypass this problem as per my understanding.
- I hope to find a solution for this so that this web app is perfectly usable to scrap a feasable number of reviews for sentiment analysis of any product.
Thank You for reading this post. If this post helped you out in anyway reach out to me on twitter and let me know! Thanks.